

群客微信多开微信群多功能营销管理系统(电脑版)-全功能介绍完整版群客助手-微信社群管理助手,依托强大的 AI 智能,实现微信群自管理、自运营,助力您的社群运营营销裂变之路。是微信社群营销不可或缺的工具软件,一款24小时自动运...
-
发布了文章 2022-01-02

置顶群客微信多开微信群营销管理系统-社群助手(电脑版)
-
发布了文章 2022-05-23

置顶微信加好友综合营销电脑版-间隔策略,权重匹配,365天自动加人机器人
微信加好友-微信综合营销系统电脑版-间隔策略,权重匹配,365天自动加人机器人在微信号比软件贵的年代,在企业私域运营管理过程中,软件的安全性,稳定性,可靠性,一直是重中之重!一、当前微信加好友软件存在的问题提 高 通 过 率...
-
发布了文章 2022-06-22

置顶企业微信多开企业微信社群营销管理系统(电脑版)
企业微信社群营销管理系统第三方辅助软件温馨提示:1、所有软件先下载安装(360卫士卸载,电脑软件需关闭系统防火墙),没问题能打开激活码页面再购买激活码! 2、所有软件一经激活,请勿升级系统,或者重装系统,一旦出现问...
-

开源力量公开课第三十一期- Nutch:从搜索引擎到网络爬虫
开源力量公开课第三十一期- Nutch:从搜索引擎到网络爬虫 开源力量公开课,每周二晚线上线下同时开课,让我们一起向IT技术大牛们学习! 课程题目: 开源力量公开课第三十一期- Nutch:从搜索引擎到网络爬虫 开...
-

爬虫网站——Google的下一个目标
北京时间2006年2月23日,记者获悉,Google发布一款免费的在线网页创建工具,用户可以通过此工具可以在短短数分钟内创建自己的网页或出版物,且不受任何时间和地点的限制,只要能上网就能制作出...
-

爬虫使用代理服务器的简要思路
爬虫有的时候会遇到被禁代理的情况,这个时候你可以找一下代理网站,抓取一下免费的代理,来进行动态的轮询就没问题了,也可以用别人做好的第三方代理平台,比如说亿牛云代理,是一个代理是基于Linux系统研发的平台,自营线路,电信...
-

网络爬虫的入罪标准与路径研究
网络爬虫的入罪标准与路径研究 人民检察编辑部 最高人民检察院 8月18日 网络爬虫(Web Crawler),又称网络蜘蛛或者网络机器人,是一种按照一定规则自动抓取互联网信息的程序。在大数据时...
-

PDF搜索工具内是不是也有一个“爬虫”?
“Filter”这个英文单词直译为过滤、搜索。提到“搜索”,大家立马联想到的就是——搜索引擎,因为百度、google等知名搜索引擎的广泛运用,为用户提供检索服务,极大地方便了网民对互联网的运用。据数据显示,中国4亿的网民平均...
-

网络爬虫原理 网络爬虫是什么
最近总听到一个熟悉而陌生的名词“网络爬虫”,到底什么是网络爬虫呢?小编和大家一起来探究一下“网络爬虫”。 网络爬虫是什么 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网...
-

谁知道什么是网络爬虫呢?
网络爬虫网络爬虫的分类编辑网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(GeneralPurposeWebCrawler)、聚焦网络爬虫(FocusedWebCrawler)、增量式网络爬虫(Inc...
-

关于python爬虫
如何运行爬虫代码,爬虫代码有很多,这里列举最常见的爬虫代码的运行方法工具/原料有python环境的pc一台方法/步骤打开python爬虫代码的源码目录,通常开始文件为,init.py,start.py,app.py寻找有没有...
-
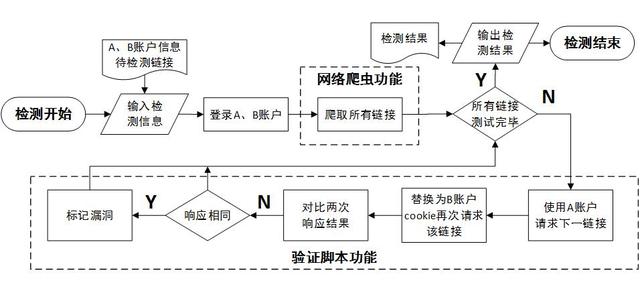
软件测试之爬虫测试
很多同学不知道爬虫应该怎么进行测试,我也是刚接触过一点爬虫测试的小白,通过对爬虫的分析,总结了爬虫的测试方法,有其他建议的欢迎补充。 一、测试阶段 对于需要调用第三方平台(比如魔蝎 进行数据采集的流程,大家可能比较熟...
-

PHP数据采集发布爬虫软件
速上采集器是一款免费的数据采集发布爬虫软件,采用php+mysql开发,可部署在云服务器,几乎能采集所有类型的网页,无缝对接各类CMS建站程序,免登录实时发布数据,全自动无需人工干预!是大数据、云时代网站数据自动化采集的最佳...
-

利用「爬虫软件」获取 11.8 亿条隐私数据,包含手机号码
利用「爬虫软件」获取 11.8 亿条隐私数据,包含手机号码逯某,男,1978年出生,河南省商丘市人,本科文化,无业。因涉嫌非法获取计算机信息系统数据、非法控制计算机信息系统罪,于2020年8月15日被商丘市公安局新城分局刑事...
-
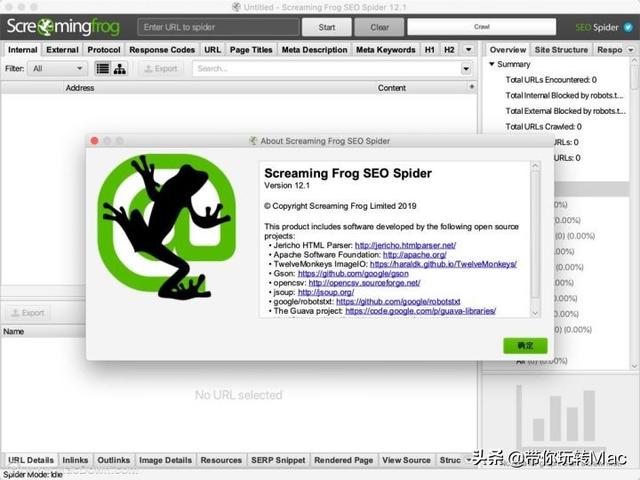
尖叫青蛙网络爬虫软件
Screaming Frog SEO Spider for Mac是一款专门用于抓取网址进行分析的网络爬虫开发工具,你可以通过这款软件来快速抓取网站中可能出现的损坏链接和服务器错误,或是识别网站中临时、永久重定向的链接循坏,...
-

爬虫平台 spider-flow
介绍spider-flow,新一代爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。特性支持 css 选择器、正则提取支持 JSON/XML 格式支持 Xpath/JsonPath 提取支持多数据源、SQL sele...
-

终于有人把网络爬虫讲明白了
导读:人们正在以前所未有的速度转向互联网,我们在互联网上所做的很多行为产生了大量的“用户数据”,比如微博、购买记录等。互联网成了海量信息的载体;互联网目前是分析市场趋势、监视竞争对手或者获取销售线索的最佳场所,数据采集以及分...
-
入门爬虫,爬取数据这一篇就够了
有小伙伴问,新手该怎么开始学习爬虫。其实说实在的入门爬虫真的非常容易。于是我就针对如何入门爬虫进行了总结如果你不会用爬虫爬数据,但是你又经常需要把某些网站上的数据导入到Excel等软件,那么请阅读本文,拉到最底!前段时间想换...
-
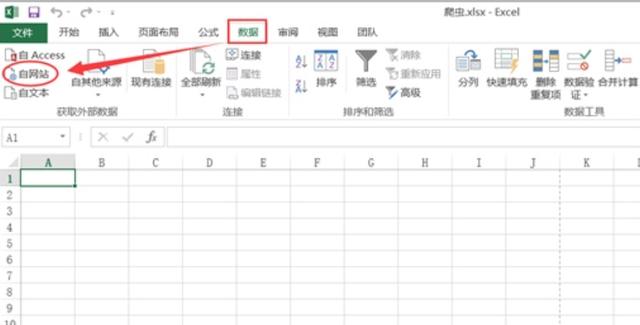
8个零代码数据爬取工具,不会Python也能轻松爬数!(附教程)
前天给大家整理了免费数据源网站合集,看大家的反馈很积极,有粉丝留言说,她还想要爬取一些网页的数据进行分析,不知道该如何下手目前的用的比较多数据爬取方法是用python爬虫,这两年python很火,网上关于python爬虫的教...
-
爬虫、C++、JAVA,将来哪个比较有前途?
谢邀,说一下我的观点:1.爬虫是一种工具,用很多语言都可以实现。Python现在越来越多的应用到爬虫,数据分析,人工智能领域,未来的火热与前途绝对比老牌Java要好很多。2.Java和c++作为来牌强劲语言,现在的市场也不可...
-

Python什么爬虫库好用?
Python下的爬虫库,一般分为3类。抓取类urllib(Python3 ,这是Python自带的库,可以模拟浏览器的请求,获得Response用来解析,其中提供了丰富的请求手段,支持Cookies、Headers等各类参数...
-

写Python爬虫一定要用到chromedriver吗?
如果是让我写,我优先选用selenium(chromedriver ,模拟正常浏览。效率低很多,但是数据靠谱。爬虫与反爬,就像生存与死亡,是一个值得考虑到问题。写爬虫,目的是获得数据。如果是简单、无争议公开的数据,只要不对服...
-

一般用哪些工具做大数据分析?
感谢邀请,大数据分析是指对规模巨大的数据进行分析。大数据可以概括为5个V, 数据量大(Volume 、速度快(Velocity 、类型多(Variety 、价值(Value 、真实性(Veracity 。随着大数据时代的来临...
-

爬虫在哪里可以学习,出来能找到工作吗?
爬虫学习不难,如果时间充足完全可以自己学习。没有必要去什么地方学习。先从Python基础学起,学完就可以进去爬虫的学习了。过程都不难,每天两小时,三个月就可以入门了。以后的就是晋级的事了。但是对于就业来说的话,只会爬虫很难找...
-
有没有网站数据抓取的软件?
也算是入乡随俗,如果是不在乎具体某个网站,单分析某个词出现的频率,大概率要提到百度指数,毕竟百度目前在中文互联网搜索引擎市场份额最大,百度指数又是基于海量网民搜索行为数据加以分析,因此目前也是企业经营决策的重要依据。比如某一...
-
学习python的爬虫用先学习html吗?
最好学习一下,不要求熟悉,但必须要会,我们爬虫所爬取的网页数据大部分都会直接或间接嵌套在html标签或属性中,如果你对html一点都不了解,也就无从谈及数据的解析和提取,下面我简单介绍一下python爬虫的学习过程,感兴趣的...
